This documentation only applies to any version of AnythingLLM 1.8.5 and above.
Using Documents in AnythingLLM
Leveraging custom and uploaded documents in your chats is the most powerful use-case for AnythingLLM has a fully customizable document management system that is both easy to use and powerful right out of the box.
AnythingLLM supports both attaching documents and embedding documents (RAG & Reranking) for your convenience and flexibility.
Attaching documents in chat
Uploaded documents in the chat are workspace and thread scoped. This means that documents uploaded in one thread will not be available in another chat. If you want a document to be available in multiple threads, you will need to upload it to the workspace as an embedded document.
Using documents in chat is simple - simply drag and drop your documents into the chat window or click on the + icon in the prompt input.
Documents and Context
By default, AnythingLLM will insert the full text of your documents into the chat window. This is a powerful feature, but it can also be overwhelming for really large documents or situations where the model's context window is limited.
If you exceed the context window while adding documents, AnythingLLM will ask you if you want to chunk the documents into smaller pieces (aka: embed). Embedding documents is called RAG and is a powerful technique that allows LLMs to use external data sources to answer questions without
overloading the model's context window. There are tradeoffs to this approach, but it is a powerful way to get the best of both worlds.
You can monitor the context window size in the chat window by hovering over the + icon in the prompt input when documents are attached to the chat. Which is denoted by the number above the + icon.

You exceed the context window - what now?
If you exceed the context window of your current model, AnythingLLM will ask you if you want to chunk the documents into smaller pieces (aka: embed).
Embedding documents is called RAG and is a powerful technique that allows LLMs to use external data sources to answer questions without

Cancel: Will remove the documents from the chat window.
Continue Anyway: Will continue to add the document full text to the chat window, but data will be lost in this process as AnythingLLM will automatically prune the context to fit. You should not do this as you will expierence inaccurate LLM behavior.
Embed: Will embed the document (RAG) and add it to the workspace. This will allow the LLM to use the document as a source of information, but it will not be able to use the full text of the document. This option may or may not be visible depending on your permissions on the workspace.
Embedding a document makes the document available to every thread in the workspace.
In multi-user mode, embedding a document will make the document available to every user who has access to the workspace.
RAG vs Attached Documents
RAG (Retrieval Augmented Generation)
RAG is a technique of splitting and chunking documents into smaller pieces and only retrieving a small amount of semantically relevant context to the LLM. This reduces the amount of information the LLM has to process, but it also reduces the amount of information the LLM can use to answer the question.
Attached Documents
Attached documents are documents that are uploaded to the workspace and are available to the LLM. This means that the LLM can use the full text of the document to answer the question. This will take longer and potentially cost more to process but your answers will be very accurate.
RAG settings
AnythingLLM exposes many many options to tune your workspace to better fit with your selection of LLM, embedder, and vector database.
The workspace options are the easiest to mess with and you should start there first. AnythingLLM makes some default assumptions in each workspace. These work for some but certainly not all use cases.
You can find these settings by hovering over a workspace and clicking the "Gear" icon.
Vector Database Settings > Search Preference (Reranking)
For now, this option is only available if you are using LanceDB (default) as your vector database.
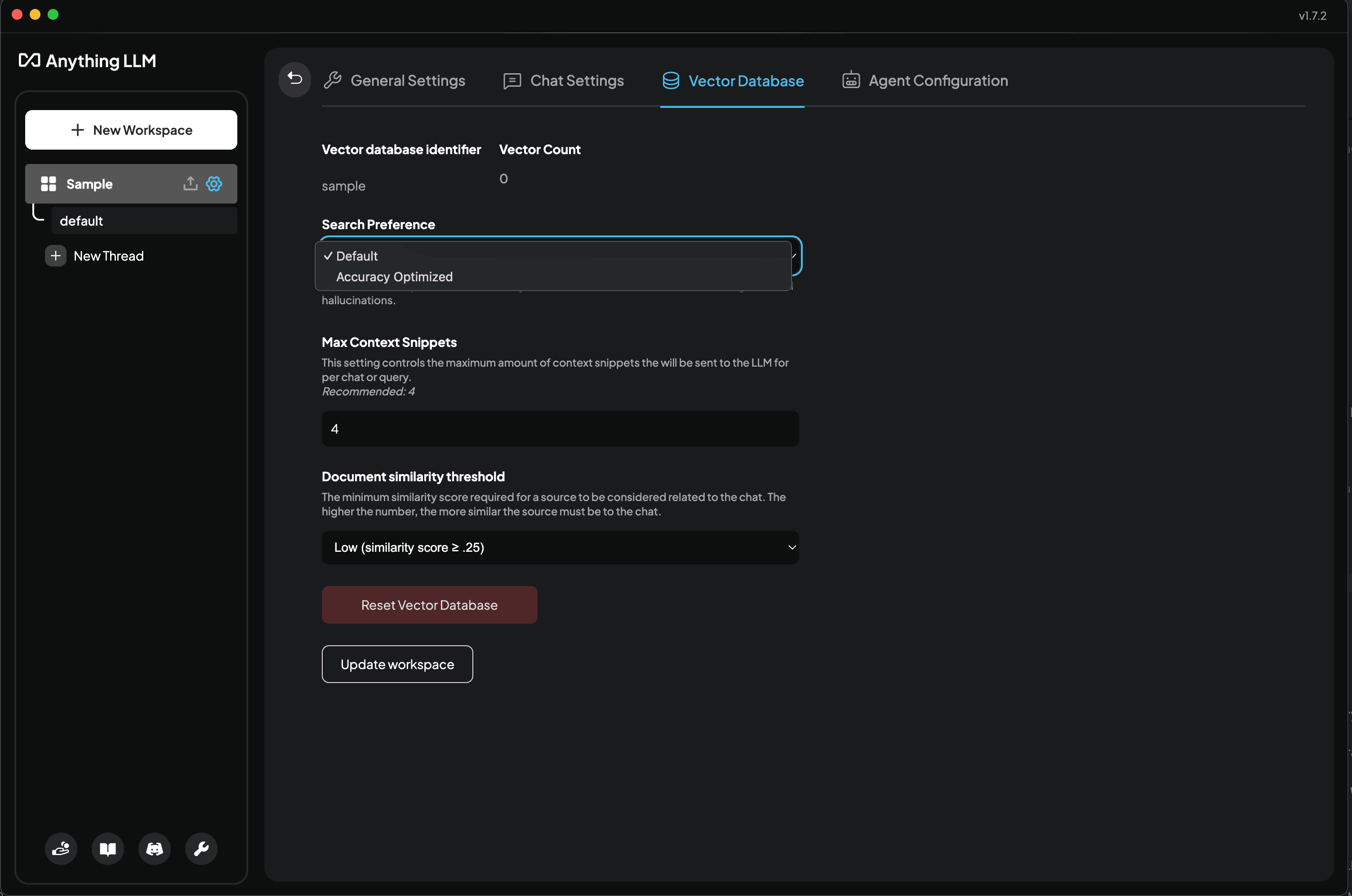
By default, AnythingLLM will search for the most relevant chunks of text. For the majority of use cases this is the best option since it is very simple to run and very fast to calculate.
However, if you are getting bad results, you may want to try "Accuracy Optimized" instead. This will search more chunks of text and then re-rank them to the top chunks that are most relevant to your query. This process is slightly slower but will yield better results in almost all cases.
Reranking is computationally more expensive and on slower machines it may take more time that the you are willing to wait. Like the embedder model, this model will download once on it's first use. This is a workspace specific setting so you can experiment with it in different workspaces.
From our testing, the reranking process will add about 100-500ms to the response time depending on your computer or instance performance.
Vector Database Settings > Max Context Snippets
This is a very critical item during the "retrieval" part of RAG. This determines "How many relevant snippets of text do I want to send to the LLM". Intuitively you may think "Well, I want all of them", but that is not possible since there is an upper limit to how many tokens each model can process. This window, called the context window, is shared with the system prompt, context, query, and history.
AnythingLLM will trim data from the context if you are going to overflow the model - which will crash it. So it's best to keep this value anywhere from 4-6 for the majority of models. If using a large-context model like Claude-3, you can go higher but beware that too much "noise" in the context may mislead the LLM in response generation.
Vector Database Settings > Document similarity threshold
This setting is likely the cause of the issue you are having! This property will filter out low-scoring vector chunks that are likely irrelevant to your query. Since this is based on mathematical values and not based on the true semantic similarity it is possible the text chunk that contains your answer was filtered out.
If you are getting hallucinations or bad LLM responses, you should set this to No Restriction. By default the minimum score is 20%, which works for some but this calculated values depends on several factors:
- Embedding model used (dimensions and ability to vectorize your specific text)
- Example: An embedder used to vectorize English text may not do well on Mandarin text.
- The default embedder is https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 (opens in a new tab)
- The density of vectors in your specific workspace.
- More vectors = more possible noise, and matches that are actually irrelevant.
- Your query: This is what the matching vector is based on. Vague queries get vague results.
Document Pinning
As a last resort, if the above settings do not seem to change anything for you - then document pinning may be a good solution.
Document Pinning is where we do a full-text insertion of the document into the context window. If the context window permits this volume of text, you will get full-text comprehension and far better answers at the expense of speed and cost.
Document Pinning should be reserved for documents that can either fully fit in the context window or are extremely critical for the use-case of that workspace.
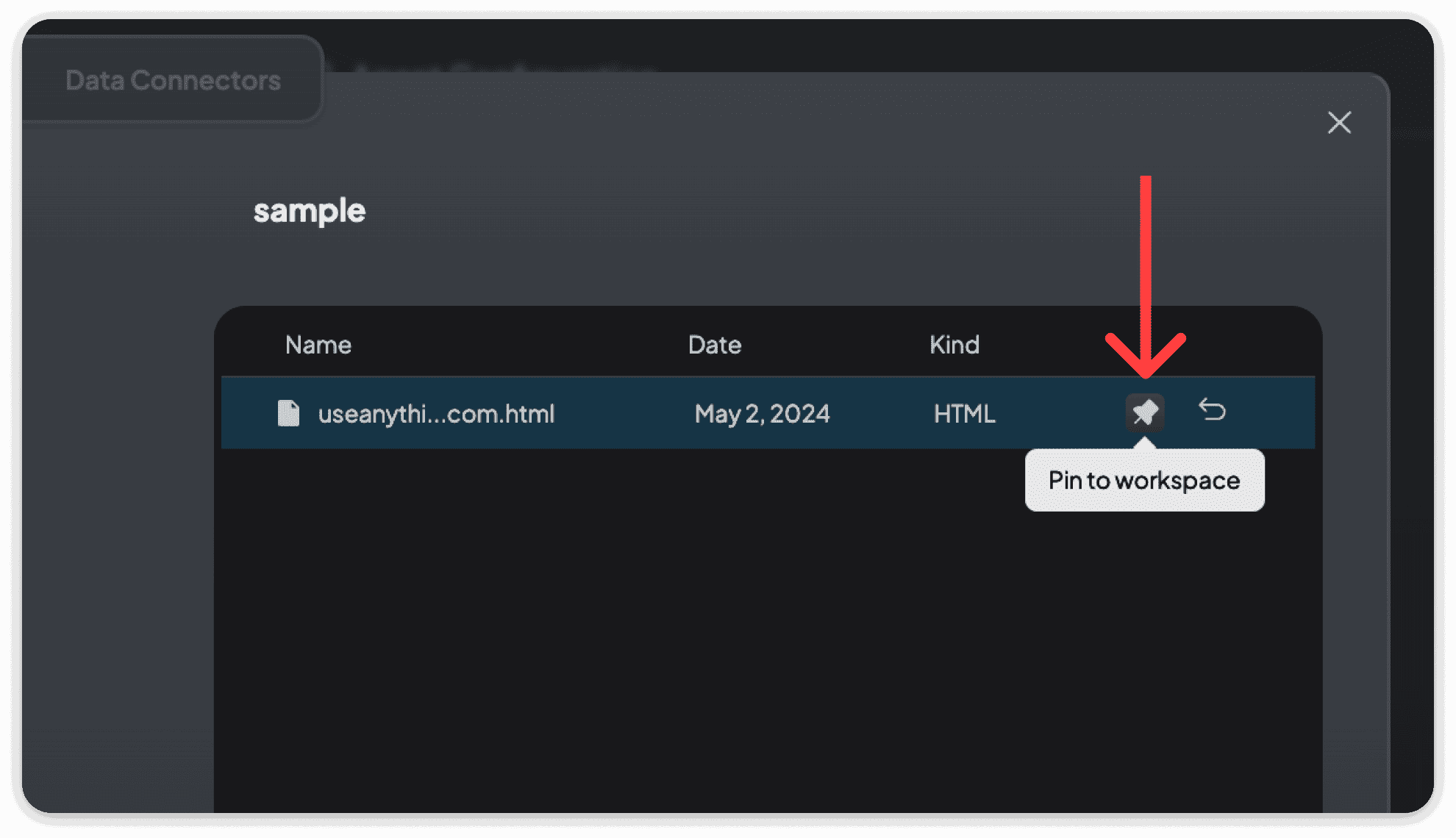
You can only pin a document that has already been embedded. Clicking the pushpin icon will toggle this setting for the document. Pinned documents will not be duplicated as RAG results and are excluded from the RAG process.